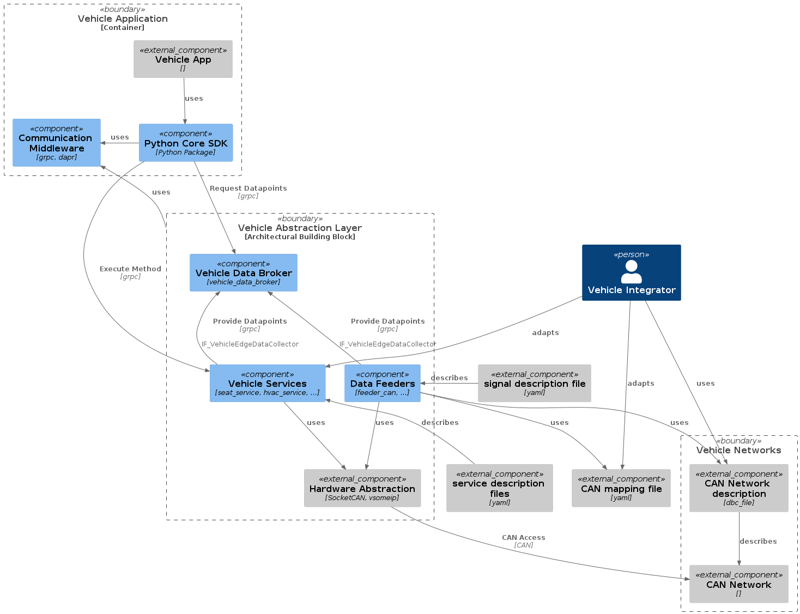
The Vehicle Abstraction Layer (VAL) enables access to the systems and functions of a vehicle via a unified - or even better - a standardized Vehicle API abstracting from the details of the end-to-end architecture of the vehicle. The unified API enables Vehicle Apps to run on different vehicle architectures of a single OEM. Vehicle Apps can be even implemented OEM-agnostic, if using an API based on a standard like the
COVESA Vehicle Signal Specification (VSS)
.
The Vehicle API eliminates the need to know the source, destination, and format of signals for the vehicle system.
The Eclipse Velocitas project is using the
Eclipse KUKSA project
.
KUKSA does not provide a concrete VAL. That’s up to you as an OEM (vehicle manufacturer) or as a supplier.
But KUKSA provides the components and tools that helps you to implement a VAL for your chosen end-to-end architecture. Also, it can support you to simulate the vehicle hardware during the development phase of an Vehicle App or Service.
KUKSA provides you with ready-to-use generic components for the signal-based access to the vehicle, like the KUKSA Databroker and the generic Data Providers (aka Data Feeders).
It also provides you reference implementations of certain Vehicle Services, like the Seat Service and the HVAC Service.
The
KUKSA Databroker
is a gRPC service acting as a broker of vehicle data / signals also called data points in the following.
It provides central access to vehicle data points arranged in a - preferably standardized - vehicle data model like the COVESA VSS or others. But this is not a must, it is also possible to use your own (proprietary) vehicle model or to extend the COVESA VSS with your specific extensions via
VSS overlays
.
Data points represent certain states of a vehicle, like the current vehicle speed or the currently applied gear. Data points can represent sensor values like the vehicle speed or engine temperature, actuators like the wiper mode, and immutable attributes of the vehicle like the needed fuel type(s) of the vehicle, engine displacement, maximum power, etc.
Data points factually belonging together are typically arranged in branches and sub-branches of a tree structure (like
this example
on the COVESA VSS site).
The KUKSA Databroker is implemented in Rust, can run in a container and provides services to get data points, update data points and for subscribing to automatic notifications on data point changes.
Filter- and rule-based subscriptions of data points can be used to reduce the number of updates sent to the subscriber.
Data Providers / Data Feeders
Conceptually, a data provider is the responsible to take care for a certain set of data points: It provides updates of sensor data from the vehicle to the Databroker and forwards updates of actuator values to the vehicle. The set of data points a data provider maintains may depend on the network interface (e.g. CAN bus) via that those data is accessible or it can depend on a certain use case the provider is responsible for (like seat control).
Eclipse KUKSA provides several genericData Providers
for different datasources.
As of today, Eclipse Velocitas only utilizes the generic
CAN Provider (KUKSA CAN Provider)
implemented in Python, which reads data from a CAN bus based on mappings specified in e.g. a CAN network description (dbc) file.
The feeder uses a mapping file and data point metadata to convert the source data to data points and injects them into the Databroker using its Collector gRPC interface.
The feeder automatically reconnects to the Databroker in the event that the connection is lost.
Vehicle Services
A vehicle service offers a Vehicle App to interact with the vehicle systems on a RPC-like basis.
It can provide service interfaces to control actuators or to trigger (complex) actions, or provide interfaces to get data.
It communicates with the Hardware Abstraction to execute the underlying services, but may also interact with the Databroker.
The
KUKSA Incubation repository
contains examples illustrating how such kind of vehicle services can be built.
Hardware Abstraction
Data feeders rely on hardware abstraction. Hardware abstraction is project/platform specific.
The reference implementation relies on SocketCAN and vxcan, see
KUKSA CAN Provider
.
The hardware abstraction may offer replaying (e.g., CAN) data from a file (can dump file) when the respective data source (e.g., CAN) is not available.
Overview of the VAL architecture
Information Flow
The VAL offers an information flow between vehicle networks and vehicle services.
The data that can flow is ultimately limited to the data available through the Hardware Abstraction, which is platform/project-specific.
The KUKSA Databroker offers read/subscribe access to data points based on a gRPC service. The data points which are actually available are defined by the set of feeders providing the data into the broker.
Services (like the
seat service
) define which CAN signals they listen to and which CAN signals they send themselves, see
documentation
.
Service implementations may also interact as feeders with the Databroker.
Data flow when a Vehicle App uses the KUKSA Databroker
Architectural representation of the KUKSA Databroker data flow
Data flow when a Vehicle App uses a Vehicle Service
Architectural representation of the vehicle service data flow
Source Code
Source code and build instructions are available in the respective KUKSA repositories:
This provides a style guide for .proto files. By following these conventions, you’ll make your protocol buffer message definitions and their corresponding classes consistent and easy to read.
Unless otherwise indicated, this style guide is based on the style guide from
google protocol-buffers style
under Apache 2.0 License & Creative Commons Attribution 4.0 License.
Note that protocol buffer style can evolve over time, so it is likely that you will see .proto files written in different conventions or styles. Please respect the existing style when you modify these files. Consistency is key. However, it is best to adopt the current best style when you are creating a new .proto file.
Standard file formatting
Keep the line length to 80 characters.
Use an indent of 2 spaces.
Prefer the use of double quotes for strings.
File structure
Files should be named lower_snake_case.proto
All files should be ordered in the following manner:
License header
File overview
Syntax
Package
Imports (sorted)
File options
Everything else
Directory Structure
Files should be stored in a directory structure that matches their package sub-names. All files
in a given directory should be in the same package.
Below is an example based on the
proto files
in the kuksa.-databroker repository.
| proto/
| └── sdv
| └── databroker
| └── v1 // package sdv.databroker.broker.v1
| ├── broker.proto // service Broker in sdv.databroker.broker.v1
| ├── collector.proto // service Collector in sdv.databroker.broker.v1
| └── types.proto // type definition and import of in sdv.databroker.broker.v1
Package names should be in lowercase. Package names should have unique names based on the project name, and possibly based on the path of the file containing the protocol buffer type definitions.
Message and field names
Use PascalCase (CamelCase with an initial capital) for message names – for example, SongServerRequest. Use underscore_separated_names for field names (including oneof field and extension names) – for example, song_name.
If your field name contains a number, the number should appear after the letter instead of after the underscore. For example, use song_name1 instead of song_name_1
Repeated fields
All API interfaces must provide a major version number, which is encoded at the end of the protobuf package.
If an API introduces a breaking change, such as removing or renaming a field, it must increment its API version number to ensure that existing user code does not suddenly break.
Note: The use of the term “major version number” above is taken from semantic versioning. However, unlike in traditional semantic versioning, APIs must not expose minor or patch version numbers.
For example, APIs use v1, not v1.0, v1.1, or v1.4.2. From a user’s perspective, minor versions are updated in place, and users receive new functionality without migration.
A new major version of an API must not depend on a previous major version of the same API. An API may depend on other APIs, with an expectation that the caller understands the dependency and stability risk associated with those APIs. In this scenario, a stable API version must only depend on stable versions of other APIs.
Different versions of the same API should preferably be able to work at the same time within a single client application for a reasonable transition period. This time period allows the client to transition smoothly to the newer version. An older version must go through a reasonable, well-communicated deprecation period before being shut down.
For releases that have alpha or beta stability, APIs must append the stability level after the major version number in the protobuf package.
Release-based versioning
An individual release is an alpha or beta release that is expected to be available for a limited time period before its functionality is incorporated into the stable channel, after which the individual release will be shut down.
When using release-based versioning strategy, an API may have any number of individual releases at each stability level.
Alpha and beta releases must have their stability level appended to the version, followed by an incrementing release number. For example, v1beta1 or v1alpha5. APIs should document the chronological order of these versions in their documentation (such as comments).
Each alpha or beta release may be updated in place with backwards-compatible changes. For beta releases, backwards-incompatible updates should be made by incrementing the release number and publishing a new release with the change. For example, if the current version is v1beta1, then v1beta2 is released next.
The gRPC protocol is designed to support services that change over time. Generally, additions to gRPC services and methods are non-breaking. Non-breaking changes allow existing clients to continue working without changes. Changing or deleting gRPC services are breaking changes. When gRPC services have breaking changes, clients using that service have to be updated and redeployed.
Making non-breaking changes to a service has a number of benefits:
Existing clients continue to run.
Avoids work involved with notifying clients of breaking changes, and updating them.
Only one version of the service needs to be documented and maintained.
Non-breaking changes
These changes are non-breaking at a gRPC protocol level and binary level.
Adding a new service
Adding a new method to a service
Adding a field to a request message - Fields added to a request message are deserialized with the default value on the server when not set. To be a non-breaking change, the service must succeed when the new field isn’t set by older clients.
Adding a field to a response message - Fields added to a response message are deserialized into the message’s unknown fields collection on the client.
Adding a value to an enum - Enums are serialized as a numeric value. New enum values are deserialized on the client to the enum value without an enum name. To be a non-breaking change, older clients must run correctly when receiving the new enum value.
Binary breaking changes
The following changes are non-breaking at a gRPC protocol level, but the client needs to be updated if it upgrades to the latest .proto contract. Binary compatibility is important if you plan to publish a gRPC library.
Removing a field - Values from a removed field are deserialized to a message’s unknown fields. This isn’t a gRPC protocol breaking change, but the client needs to be updated if it upgrades to the latest contract. It’s important that a removed field number isn’t accidentally reused in the future. To ensure this doesn’t happen, specify deleted field numbers and names on the message using Protobuf’s reserved keyword.
Renaming a message - Message names aren’t typically sent on the network, so this isn’t a gRPC protocol breaking change. The client will need to be updated if it upgrades to the latest contract. One situation where message names are sent on the network is with Any fields, when the message name is used to identify the message type.
Nesting or unnesting a message - Message types can be nested. Nesting or unnesting a message changes its message name. Changing how a message type is nested has the same impact on compatibility as renaming.
Protocol breaking changes
The following items are protocol and binary breaking changes:
Renaming a field - With Protobuf content, the field names are only used in generated code. The field number is used to identify fields on the network. Renaming a field isn’t a protocol breaking change for Protobuf. However, if a server is using JSON content, then renaming a field is a breaking change.
Changing a field data type - Changing a field’s data type to an incompatible type will cause errors when deserializing the message. Even if the new data type is compatible, it’s likely the client needs to be updated to support the new type if it upgrades to the latest contract.
Changing a field number - With Protobuf payloads, the field number is used to identify fields on the network.
Renaming a package, service or method - gRPC uses the package name, service name, and method name to build the URL. The client gets an UNIMPLEMENTED status from the server.
Removing a service or method - The client gets an UNIMPLEMENTED status from the server when calling the removed method.
Behavior breaking changes
When making non-breaking changes, you must also consider whether older clients can continue working with the new service behavior. For example, adding a new field to a request message:
Isn’t a protocol breaking change.
Returning an error status on the server if the new field isn’t set makes it a breaking change for old clients.
Behavior compatibility is determined by your app-specific code.
The framework for drafting error messages could be useful as a later improvement. This could e.g., be used to specify which unit created the error message and to assure the same structure on all messages. The latter two may e.g., depend on debug settings, e.g., error details only in debug-builds to avoid leaks of sensitive information. A global function like below or similar could handle that and also possibly convert between internal error codes and gRPC codes.
grpc::Statusstatus=CreateStatusMessage(PERMISSION_DENIED,"DataBroker","Rule access rights violated");
SDV error handling for gRPC interfaces (e.g., VAL vehicles services)
Use gRPC error codes as base
Document in proto files (as comments) which error codes that the service implementation can emit and the meaning of them. (Errors that only are emitted by the gRPC framework do not need to be listed.)
Do not - unless there are special reasons - add explicit error/status fields to rpc return messages.
Additional error information can be given by free text fields in gRPC error codes. Note, however, that sensitive information like Given password ABCD does not match expected password EFGH should not be passed in an unprotected/unencrypted manner.
SDV handling of gRPC error codes
The table below gives error code guidelines for each gRPC on:
If it is relevant for a client to retry the call or not when receiving the error code. Retry is only relevant if the error is of a temporary nature.
When to use the error code when implementing a service.
gRPC error code
Retry Relevant?
Recommended SDV usage
OK
No
Mandatory error code if operation succeeded. Shall never be used if operation failed.
CANCELLED
No
No explicit use case on server side in SDV identified
UNKNOWN
No
To be used in default-statements when converting errors from e.g., Broker-errors to SDV/gRPC errors
INVALID_ARGUMENT
No
E.g., Rule syntax with errors
DEADLINE_EXCEEDED
Yes
Only applicable for asynchronous services, i.e. services which wait for completion before the result is returned. The behavior if an operation cannot finish within expected time must be defined. Two options exist. One is to return this error after e.g., X seconds. Another is that the server never gives up, but rather waits for the client to cancel the operation.
NOT_FOUND
No
Long term situation that likely not will change in the near future. Example: SDV can not find the specified resource (e.g., no path to get data for specified seat)
ALREADY_EXISTS
No
No explicit use case on server side in SDV identified
PERMISSION_DENIED
No
Operation rejected due to permission denied
RESOURCE_EXHAUSTED
Yes
Possibly if e.g., malloc fails or similar errors.
FAILED_PRECONDITION
Yes
Could be returned if e.g., operation is rejected due to safety reasons. (E.g., vehicle moving)
ABORTED
Yes
Could e.g., be returned if service does not support concurrent requests, and there is already either a related operation ongoing or the operation is aborted due to a newer request received. Could also be used if an operation is aborted on user/driver request, e.g., physical button in vehicle pressed.
OUT_OF_RANGE
No
E.g., Arguments out of range
UNIMPLEMENTED
No
To be used if certain use-cases of the service are not implemented, e.g., if recline cannot be adjusted
INTERNAL
No
Internal errors, like exceptions, unexpected null pointers and similar
UNAVAILABLE
Yes
To be used if the service is temporarily unavailable, e.g., during system startup.
DATA_LOSS
No
No explicit use case identified on server side in SDV.
UNAUTHENTICATED
No
No explicit use case identified on server side in SDV.